
[fusion_builder_container type=”flex” hundred_percent=”no” hundred_percent_height=”no” hundred_percent_height_scroll=”no” align_content=”stretch” flex_align_items=”flex-start” flex_justify_content=”flex-start” hundred_percent_height_center_content=”yes” equal_height_columns=”no” container_tag=”div” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” status=”published” border_style=”solid” box_shadow=”no” box_shadow_blur=”0″ box_shadow_spread=”0″ gradient_start_position=”0″ gradient_end_position=”100″ gradient_type=”linear” radial_direction=”center center” linear_angle=”180″ background_position=”center center” background_repeat=”no-repeat” fade=”no” background_parallax=”none” enable_mobile=”no” parallax_speed=”0.3″ background_blend_mode=”none” video_aspect_ratio=”16:9″ video_loop=”yes” video_mute=”yes” absolute=”off” absolute_devices=”small,medium,large” sticky=”off” sticky_devices=”small-visibility,medium-visibility,large-visibility” sticky_transition_offset=”0″ scroll_offset=”0″ animation_direction=”left” animation_speed=”0.3″ filter_hue=”0″ filter_saturation=”100″ filter_brightness=”100″ filter_contrast=”100″ filter_invert=”0″ filter_sepia=”0″ filter_opacity=”100″ filter_blur=”0″ filter_hue_hover=”0″ filter_saturation_hover=”100″ filter_brightness_hover=”100″ filter_contrast_hover=”100″ filter_invert_hover=”0″ filter_sepia_hover=”0″ filter_opacity_hover=”100″ filter_blur_hover=”0″][fusion_builder_row][fusion_builder_column type=”1_1″ layout=”1_1″ align_self=”auto” content_layout=”column” align_content=”flex-start” valign_content=”flex-start” content_wrap=”wrap” spacing=”” center_content=”no” link=”” target=”_self” min_height=”” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” sticky_display=”normal,sticky” class=”” id=”” type_medium=”” type_small=”” order_medium=”0″ order_small=”0″ dimension_spacing_medium=”” dimension_spacing_small=”” dimension_spacing=”” dimension_margin_medium=”” dimension_margin_small=”” margin_top=”” margin_bottom=”” padding_medium=”” padding_small=”” padding_top=”” padding_right=”” padding_bottom=”” padding_left=”” hover_type=”none” border_sizes=”” border_color=”” border_style=”solid” border_radius=”” box_shadow=”no” dimension_box_shadow=”” box_shadow_blur=”0″ box_shadow_spread=”0″ box_shadow_color=”” box_shadow_style=”” background_type=”single” gradient_start_color=”” gradient_end_color=”” gradient_start_position=”0″ gradient_end_position=”100″ gradient_type=”linear” radial_direction=”center center” linear_angle=”180″ background_color=”” background_image=”” background_image_id=”” background_position=”left top” background_repeat=”no-repeat” background_blend_mode=”none” render_logics=”” filter_type=”regular” filter_hue=”0″ filter_saturation=”100″ filter_brightness=”100″ filter_contrast=”100″ filter_invert=”0″ filter_sepia=”0″ filter_opacity=”100″ filter_blur=”0″ filter_hue_hover=”0″ filter_saturation_hover=”100″ filter_brightness_hover=”100″ filter_contrast_hover=”100″ filter_invert_hover=”0″ filter_sepia_hover=”0″ filter_opacity_hover=”100″ filter_blur_hover=”0″ animation_type=”” animation_direction=”left” animation_speed=”0.3″ animation_offset=”” last=”true” border_position=”all” first=”true”][fusion_text columns=”” column_min_width=”” column_spacing=”” rule_style=”default” rule_size=”” rule_color=”” content_alignment_medium=”” content_alignment_small=”” content_alignment=”” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” sticky_display=”normal,sticky” class=”” id=”” margin_top=”” margin_right=”” margin_bottom=”” margin_left=”” font_size=”” fusion_font_family_text_font=”” fusion_font_variant_text_font=”” line_height=”” letter_spacing=”” text_color=”” animation_type=”” animation_direction=”left” animation_speed=”0.3″ animation_offset=””]
What is Apache Spark?
Apache Spark is an open-source, dis. tributed processing system used for big data workloads. It utilizes in-memory caching, and optimized query execution for fast analytic queries against data of any size. It provides development APIs in Java, Scala, Python and R, and supports code reuse across multiple workloads—batch processing, interactive queries, real-time analytics, machine learning, and graph processing. You’ll find it used by organizations from any industry, including at FINRA, Yelp, Zillow, DataXu, Urban Institute, and CrowdStrike. Apache Spark has become one of the most popular big data distributed processing framework with 365,000 meetup members in 2017.
[/fusion_text][fusion_text columns=”” column_min_width=”” column_spacing=”” rule_style=”default” rule_size=”” rule_color=”” content_alignment_medium=”” content_alignment_small=”” content_alignment=”” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” sticky_display=”normal,sticky” class=”” id=”” margin_top=”” margin_right=”” margin_bottom=”” margin_left=”” font_size=”” fusion_font_family_text_font=”” fusion_font_variant_text_font=”” line_height=”” letter_spacing=”” text_color=”” animation_type=”” animation_direction=”left” animation_speed=”0.3″ animation_offset=””]
Spark was discovered by apache software foundation to speed up the Hadoop computational process and overcoming its limitations. But spark is not a modified version of Hadoop. Spark has its own cluster management whereas Hadoop is one of ways to implement spark.
Apache spark is an exceptionally a cluster computing technology developed for fast computation, it depends on Hadoop map Reduce to utilize all kinds of computations. To execute spark applications faster the apache spark is used as tool. Where spark is utilizes hadoop in two ways because it has its own cluster computing management.
- Storage
- Process handling
Spark is one of the Hadoops sub venture developed by Matei Zaharia in the year 2009 at UC Berkeley’s AMPLAB. Spark was open sourced in 2010 under a BSD license and given to apache in 2013 now it is apache spark.
[/fusion_text][/fusion_builder_column][/fusion_builder_row][/fusion_builder_container][fusion_builder_container type=”flex” hundred_percent=”no” hundred_percent_height=”no” min_height_medium=”” min_height_small=”” min_height=”” hundred_percent_height_scroll=”no” align_content=”stretch” flex_align_items=”flex-start” flex_justify_content=”flex-start” flex_column_spacing=”” hundred_percent_height_center_content=”yes” equal_height_columns=”no” container_tag=”div” menu_anchor=”” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” status=”published” publish_date=”” class=”” id=”” spacing_medium=”” margin_top_medium=”” margin_bottom_medium=”” spacing_small=”” margin_top_small=”” margin_bottom_small=”” margin_top=”” margin_bottom=”” padding_dimensions_medium=”” padding_top_medium=”” padding_right_medium=”” padding_bottom_medium=”” padding_left_medium=”” padding_dimensions_small=”” padding_top_small=”” padding_right_small=”” padding_bottom_small=”” padding_left_small=”” padding_top=”” padding_right=”” padding_bottom=”” padding_left=”” link_color=”” link_hover_color=”” border_sizes=”” border_sizes_top=”” border_sizes_right=”” border_sizes_bottom=”” border_sizes_left=”” border_color=”” border_style=”solid” box_shadow=”no” box_shadow_vertical=”” box_shadow_horizontal=”” box_shadow_blur=”0″ box_shadow_spread=”0″ box_shadow_color=”” box_shadow_style=”” z_index=”” overflow=”” gradient_start_color=”” gradient_end_color=”” gradient_start_position=”0″ gradient_end_position=”100″ gradient_type=”linear” radial_direction=”center center” linear_angle=”180″ background_color=”” background_image=”” skip_lazy_load=”” background_position=”center center” background_repeat=”no-repeat” fade=”no” background_parallax=”none” enable_mobile=”no” parallax_speed=”0.3″ background_blend_mode=”none” video_mp4=”” video_webm=”” video_ogv=”” video_url=”” video_aspect_ratio=”16:9″ video_loop=”yes” video_mute=”yes” video_preview_image=”” render_logics=”” absolute=”off” absolute_devices=”small,medium,large” sticky=”off” sticky_devices=”small-visibility,medium-visibility,large-visibility” sticky_background_color=”” sticky_height=”” sticky_offset=”” sticky_transition_offset=”0″ scroll_offset=”0″ animation_type=”” animation_direction=”left” animation_speed=”0.3″ animation_offset=”” filter_hue=”0″ filter_saturation=”100″ filter_brightness=”100″ filter_contrast=”100″ filter_invert=”0″ filter_sepia=”0″ filter_opacity=”100″ filter_blur=”0″ filter_hue_hover=”0″ filter_saturation_hover=”100″ filter_brightness_hover=”100″ filter_contrast_hover=”100″ filter_invert_hover=”0″ filter_sepia_hover=”0″ filter_opacity_hover=”100″ filter_blur_hover=”0″][fusion_builder_row][fusion_builder_column type=”1_1″ layout=”1_1″ align_self=”auto” content_layout=”column” align_content=”flex-start” valign_content=”flex-start” content_wrap=”wrap” spacing=”” center_content=”no” link=”” target=”_self” min_height=”” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” sticky_display=”normal,sticky” class=”” id=”” type_medium=”” type_small=”” order_medium=”0″ order_small=”0″ dimension_spacing_medium=”” dimension_spacing_small=”” dimension_spacing=”” dimension_margin_medium=”” dimension_margin_small=”” margin_top=”” margin_bottom=”” padding_medium=”” padding_small=”” padding_top=”” padding_right=”” padding_bottom=”” padding_left=”” hover_type=”none” border_sizes=”” border_color=”” border_style=”solid” border_radius=”” box_shadow=”no” dimension_box_shadow=”” box_shadow_blur=”0″ box_shadow_spread=”0″ box_shadow_color=”” box_shadow_style=”” background_type=”single” gradient_start_color=”” gradient_end_color=”” gradient_start_position=”0″ gradient_end_position=”100″ gradient_type=”linear” radial_direction=”center center” linear_angle=”180″ background_color=”” background_image=”” background_image_id=”” background_position=”left top” background_repeat=”no-repeat” background_blend_mode=”none” render_logics=”” filter_type=”regular” filter_hue=”0″ filter_saturation=”100″ filter_brightness=”100″ filter_contrast=”100″ filter_invert=”0″ filter_sepia=”0″ filter_opacity=”100″ filter_blur=”0″ filter_hue_hover=”0″ filter_saturation_hover=”100″ filter_brightness_hover=”100″ filter_contrast_hover=”100″ filter_invert_hover=”0″ filter_sepia_hover=”0″ filter_opacity_hover=”100″ filter_blur_hover=”0″ animation_type=”” animation_direction=”left” animation_speed=”0.3″ animation_offset=”” last=”true” border_position=”all” first=”true”][fusion_separator style_type=”shadow” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” sticky_display=”normal,sticky” class=”” id=”” flex_grow=”0″ top_margin=”” bottom_margin=”” width=”” alignment=”center” border_size=”” sep_color=”” icon=”” icon_size=”” icon_color=”” icon_circle=”” icon_circle_color=”” /][/fusion_builder_column][/fusion_builder_row][/fusion_builder_container][fusion_builder_container type=”flex” hundred_percent=”no” hundred_percent_height=”no” hundred_percent_height_scroll=”no” align_content=”stretch” flex_align_items=”flex-start” flex_justify_content=”flex-start” hundred_percent_height_center_content=”yes” equal_height_columns=”no” container_tag=”div” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” status=”published” border_style=”solid” box_shadow=”no” box_shadow_blur=”0″ box_shadow_spread=”0″ gradient_start_position=”0″ gradient_end_position=”100″ gradient_type=”linear” radial_direction=”center center” linear_angle=”180″ background_position=”center center” background_repeat=”no-repeat” fade=”no” background_parallax=”none” enable_mobile=”no” parallax_speed=”0.3″ background_blend_mode=”none” video_aspect_ratio=”16:9″ video_loop=”yes” video_mute=”yes” absolute=”off” absolute_devices=”small,medium,large” sticky=”off” sticky_devices=”small-visibility,medium-visibility,large-visibility” sticky_transition_offset=”0″ scroll_offset=”0″ animation_direction=”left” animation_speed=”0.3″ filter_hue=”0″ filter_saturation=”100″ filter_brightness=”100″ filter_contrast=”100″ filter_invert=”0″ filter_sepia=”0″ filter_opacity=”100″ filter_blur=”0″ filter_hue_hover=”0″ filter_saturation_hover=”100″ filter_brightness_hover=”100″ filter_contrast_hover=”100″ filter_invert_hover=”0″ filter_sepia_hover=”0″ filter_opacity_hover=”100″ filter_blur_hover=”0″][fusion_builder_row][fusion_builder_column type=”1_1″ layout=”1_1″ align_self=”auto” content_layout=”column” align_content=”flex-start” valign_content=”flex-start” content_wrap=”wrap” spacing=”” center_content=”no” link=”” target=”_self” min_height=”” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” sticky_display=”normal,sticky” class=”” id=”” type_medium=”” type_small=”” order_medium=”0″ order_small=”0″ dimension_spacing_medium=”” dimension_spacing_small=”” dimension_spacing=”” dimension_margin_medium=”” dimension_margin_small=”” margin_top=”” margin_bottom=”” padding_medium=”” padding_small=”” padding_top=”” padding_right=”” padding_bottom=”” padding_left=”” hover_type=”none” border_sizes=”” border_color=”” border_style=”solid” border_radius=”” box_shadow=”no” dimension_box_shadow=”” box_shadow_blur=”0″ box_shadow_spread=”0″ box_shadow_color=”” box_shadow_style=”” background_type=”single” gradient_start_color=”” gradient_end_color=”” gradient_start_position=”0″ gradient_end_position=”100″ gradient_type=”linear” radial_direction=”center center” linear_angle=”180″ background_color=”” background_image=”” background_image_id=”” background_position=”left top” background_repeat=”no-repeat” background_blend_mode=”none” render_logics=”” filter_type=”regular” filter_hue=”0″ filter_saturation=”100″ filter_brightness=”100″ filter_contrast=”100″ filter_invert=”0″ filter_sepia=”0″ filter_opacity=”100″ filter_blur=”0″ filter_hue_hover=”0″ filter_saturation_hover=”100″ filter_brightness_hover=”100″ filter_contrast_hover=”100″ filter_invert_hover=”0″ filter_sepia_hover=”0″ filter_opacity_hover=”100″ filter_blur_hover=”0″ animation_type=”” animation_direction=”left” animation_speed=”0.3″ animation_offset=”” last=”true” border_position=”all” first=”true”][fusion_text columns=”” column_min_width=”” column_spacing=”” rule_style=”default” rule_size=”” rule_color=”” content_alignment_medium=”” content_alignment_small=”” content_alignment=”” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” sticky_display=”normal,sticky” class=”” id=”” margin_top=”” margin_right=”” margin_bottom=”” margin_left=”” font_size=”” fusion_font_family_text_font=”” fusion_font_variant_text_font=”” line_height=”” letter_spacing=”” text_color=”” animation_type=”” animation_direction=”left” animation_speed=”0.3″ animation_offset=””]
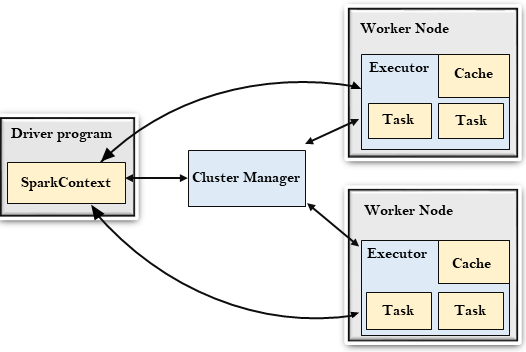
Apache Spark architecture
At a fundamental level, an Apache Spark application consists of two main components: a driver, which converts the user’s code into multiple tasks that can be distributed across worker nodes, and executors, which run on those nodes and execute the tasks assigned to them. Some form of cluster manager is necessary to mediate between the two.
Out of the box, Spark can run in a standalone cluster mode that simply requires the Apache Spark framework and a JVM on each machine in your cluster. However, it’s more likely you’ll want to take advantage of a more robust resource or cluster management system to take care of allocating workers on demand for you. In the enterprise, this will normally mean running on Hadoop YARN (this is how the Cloudera and Hortonworks distributions run Spark jobs), but Apache Spark can also run on Apache Mesos, Kubernetes, and Docker Swarm.
If you seek a managed solution, then Apache Spark can be found as part of Amazon EMR, Google Cloud Dataproc, and Microsoft Azure HDInsight. Databricks, the company that employs the founders of Apache Spark, also offers the Databricks Unified Analytics Platform, which is a comprehensive managed service that offers Apache Spark clusters, streaming support, integrated web-based notebook development, and optimized cloud I/O performance over a standard Apache Spark distribution.
Apache Spark builds the user’s data processing commands into a Directed Acyclic Graph, or DAG. The DAG is Apache Spark’s scheduling layer; it determines what tasks are executed on what nodes and in what sequence.
[/fusion_text][fusion_text columns=”” column_min_width=”” column_spacing=”” rule_style=”default” rule_size=”” rule_color=”” content_alignment_medium=”” content_alignment_small=”” content_alignment=”” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” sticky_display=”normal,sticky” class=”” id=”” margin_top=”” margin_right=”” margin_bottom=”” margin_left=”” font_size=”” fusion_font_family_text_font=”” fusion_font_variant_text_font=”” line_height=”” letter_spacing=”” text_color=”” animation_type=”” animation_direction=”left” animation_speed=”0.3″ animation_offset=””]
[/fusion_text][/fusion_builder_column][/fusion_builder_row][/fusion_builder_container][fusion_builder_container type=”flex” hundred_percent=”no” hundred_percent_height=”no” min_height_medium=”” min_height_small=”” min_height=”” hundred_percent_height_scroll=”no” align_content=”stretch” flex_align_items=”flex-start” flex_justify_content=”flex-start” flex_column_spacing=”” hundred_percent_height_center_content=”yes” equal_height_columns=”no” container_tag=”div” menu_anchor=”” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” status=”published” publish_date=”” class=”” id=”” spacing_medium=”” margin_top_medium=”” margin_bottom_medium=”” spacing_small=”” margin_top_small=”” margin_bottom_small=”” margin_top=”” margin_bottom=”” padding_dimensions_medium=”” padding_top_medium=”” padding_right_medium=”” padding_bottom_medium=”” padding_left_medium=”” padding_dimensions_small=”” padding_top_small=”” padding_right_small=”” padding_bottom_small=”” padding_left_small=”” padding_top=”” padding_right=”” padding_bottom=”” padding_left=”” link_color=”” link_hover_color=”” border_sizes=”” border_sizes_top=”” border_sizes_right=”” border_sizes_bottom=”” border_sizes_left=”” border_color=”” border_style=”solid” box_shadow=”no” box_shadow_vertical=”” box_shadow_horizontal=”” box_shadow_blur=”0″ box_shadow_spread=”0″ box_shadow_color=”” box_shadow_style=”” z_index=”” overflow=”” gradient_start_color=”” gradient_end_color=”” gradient_start_position=”0″ gradient_end_position=”100″ gradient_type=”linear” radial_direction=”center center” linear_angle=”180″ background_color=”” background_image=”” skip_lazy_load=”” background_position=”center center” background_repeat=”no-repeat” fade=”no” background_parallax=”none” enable_mobile=”no” parallax_speed=”0.3″ background_blend_mode=”none” video_mp4=”” video_webm=”” video_ogv=”” video_url=”” video_aspect_ratio=”16:9″ video_loop=”yes” video_mute=”yes” video_preview_image=”” render_logics=”” absolute=”off” absolute_devices=”small,medium,large” sticky=”off” sticky_devices=”small-visibility,medium-visibility,large-visibility” sticky_background_color=”” sticky_height=”” sticky_offset=”” sticky_transition_offset=”0″ scroll_offset=”0″ animation_type=”” animation_direction=”left” animation_speed=”0.3″ animation_offset=”” filter_hue=”0″ filter_saturation=”100″ filter_brightness=”100″ filter_contrast=”100″ filter_invert=”0″ filter_sepia=”0″ filter_opacity=”100″ filter_blur=”0″ filter_hue_hover=”0″ filter_saturation_hover=”100″ filter_brightness_hover=”100″ filter_contrast_hover=”100″ filter_invert_hover=”0″ filter_sepia_hover=”0″ filter_opacity_hover=”100″ filter_blur_hover=”0″][fusion_builder_row][fusion_builder_column type=”1_1″ layout=”1_1″ align_self=”auto” content_layout=”column” align_content=”flex-start” valign_content=”flex-start” content_wrap=”wrap” spacing=”” center_content=”no” link=”” target=”_self” min_height=”” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” sticky_display=”normal,sticky” class=”” id=”” type_medium=”” type_small=”” order_medium=”0″ order_small=”0″ dimension_spacing_medium=”” dimension_spacing_small=”” dimension_spacing=”” dimension_margin_medium=”” dimension_margin_small=”” margin_top=”” margin_bottom=”” padding_medium=”” padding_small=”” padding_top=”” padding_right=”” padding_bottom=”” padding_left=”” hover_type=”none” border_sizes=”” border_color=”” border_style=”solid” border_radius=”” box_shadow=”no” dimension_box_shadow=”” box_shadow_blur=”0″ box_shadow_spread=”0″ box_shadow_color=”” box_shadow_style=”” background_type=”single” gradient_start_color=”” gradient_end_color=”” gradient_start_position=”0″ gradient_end_position=”100″ gradient_type=”linear” radial_direction=”center center” linear_angle=”180″ background_color=”” background_image=”” background_image_id=”” background_position=”left top” background_repeat=”no-repeat” background_blend_mode=”none” render_logics=”” filter_type=”regular” filter_hue=”0″ filter_saturation=”100″ filter_brightness=”100″ filter_contrast=”100″ filter_invert=”0″ filter_sepia=”0″ filter_opacity=”100″ filter_blur=”0″ filter_hue_hover=”0″ filter_saturation_hover=”100″ filter_brightness_hover=”100″ filter_contrast_hover=”100″ filter_invert_hover=”0″ filter_sepia_hover=”0″ filter_opacity_hover=”100″ filter_blur_hover=”0″ animation_type=”” animation_direction=”left” animation_speed=”0.3″ animation_offset=”” last=”true” border_position=”all” first=”true”][fusion_separator style_type=”shadow” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” sticky_display=”normal,sticky” class=”” id=”” flex_grow=”0″ top_margin=”” bottom_margin=”” width=”” alignment=”center” border_size=”” sep_color=”” icon=”” icon_size=”” icon_color=”” icon_circle=”” icon_circle_color=”” /][/fusion_builder_column][/fusion_builder_row][/fusion_builder_container][fusion_builder_container type=”flex” hundred_percent=”no” hundred_percent_height=”no” hundred_percent_height_scroll=”no” align_content=”stretch” flex_align_items=”flex-start” flex_justify_content=”flex-start” hundred_percent_height_center_content=”yes” equal_height_columns=”no” container_tag=”div” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” status=”published” border_style=”solid” box_shadow=”no” box_shadow_blur=”0″ box_shadow_spread=”0″ gradient_start_position=”0″ gradient_end_position=”100″ gradient_type=”linear” radial_direction=”center center” linear_angle=”180″ background_position=”center center” background_repeat=”no-repeat” fade=”no” background_parallax=”none” enable_mobile=”no” parallax_speed=”0.3″ background_blend_mode=”none” video_aspect_ratio=”16:9″ video_loop=”yes” video_mute=”yes” absolute=”off” absolute_devices=”small,medium,large” sticky=”off” sticky_devices=”small-visibility,medium-visibility,large-visibility” sticky_transition_offset=”0″ scroll_offset=”0″ animation_direction=”left” animation_speed=”0.3″ filter_hue=”0″ filter_saturation=”100″ filter_brightness=”100″ filter_contrast=”100″ filter_invert=”0″ filter_sepia=”0″ filter_opacity=”100″ filter_blur=”0″ filter_hue_hover=”0″ filter_saturation_hover=”100″ filter_brightness_hover=”100″ filter_contrast_hover=”100″ filter_invert_hover=”0″ filter_sepia_hover=”0″ filter_opacity_hover=”100″ filter_blur_hover=”0″][fusion_builder_row][fusion_builder_column type=”1_1″ layout=”1_1″ align_self=”auto” content_layout=”column” align_content=”flex-start” valign_content=”flex-start” content_wrap=”wrap” spacing=”” center_content=”no” link=”” target=”_self” min_height=”” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” sticky_display=”normal,sticky” class=”” id=”” type_medium=”” type_small=”” order_medium=”0″ order_small=”0″ dimension_spacing_medium=”” dimension_spacing_small=”” dimension_spacing=”” dimension_margin_medium=”” dimension_margin_small=”” margin_top=”” margin_bottom=”” padding_medium=”” padding_small=”” padding_top=”” padding_right=”” padding_bottom=”” padding_left=”” hover_type=”none” border_sizes=”” border_color=”” border_style=”solid” border_radius=”” box_shadow=”no” dimension_box_shadow=”” box_shadow_blur=”0″ box_shadow_spread=”0″ box_shadow_color=”” box_shadow_style=”” background_type=”single” gradient_start_color=”” gradient_end_color=”” gradient_start_position=”0″ gradient_end_position=”100″ gradient_type=”linear” radial_direction=”center center” linear_angle=”180″ background_color=”” background_image=”” background_image_id=”” background_position=”left top” background_repeat=”no-repeat” background_blend_mode=”none” render_logics=”” filter_type=”regular” filter_hue=”0″ filter_saturation=”100″ filter_brightness=”100″ filter_contrast=”100″ filter_invert=”0″ filter_sepia=”0″ filter_opacity=”100″ filter_blur=”0″ filter_hue_hover=”0″ filter_saturation_hover=”100″ filter_brightness_hover=”100″ filter_contrast_hover=”100″ filter_invert_hover=”0″ filter_sepia_hover=”0″ filter_opacity_hover=”100″ filter_blur_hover=”0″ animation_type=”” animation_direction=”left” animation_speed=”0.3″ animation_offset=”” last=”true” border_position=”all” first=”true”][fusion_text columns=”” column_min_width=”” column_spacing=”” rule_style=”default” rule_size=”” rule_color=”” content_alignment_medium=”” content_alignment_small=”” content_alignment=”” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” sticky_display=”normal,sticky” class=”” id=”” margin_top=”” margin_right=”” margin_bottom=”” margin_left=”” font_size=”” fusion_font_family_text_font=”” fusion_font_variant_text_font=”” line_height=”” letter_spacing=”” text_color=”” animation_type=”” animation_direction=”left” animation_speed=”0.3″ animation_offset=””]
Spark libraries
The Spark Core engine functions partly as an application programming interface (API) layer and underpins a set of related tools for managing and analyzing data. Aside from the Spark Core processing engine, the Apache Spark API environment comes packaged with some libraries of code for use in data analytics applications. These libraries include the following:
- Spark SQL — One of the most commonly used libraries, Spark SQL enables users to query data stored in disparate applications using the common SQL language.
- Spark Streaming — This library enables users to build applications that analyze and present data in real time.
- MLlib — A library of machine learning code that enables users to apply advanced statistical operations to data in their Spark cluster and to build applications around these analyses.
- GraphX — A built-in library of algorithms for graph-parallel computation.
[/fusion_text][/fusion_builder_column][/fusion_builder_row][/fusion_builder_container][fusion_builder_container type=”flex” hundred_percent=”no” hundred_percent_height=”no” min_height_medium=”” min_height_small=”” min_height=”” hundred_percent_height_scroll=”no” align_content=”stretch” flex_align_items=”flex-start” flex_justify_content=”flex-start” flex_column_spacing=”” hundred_percent_height_center_content=”yes” equal_height_columns=”no” container_tag=”div” menu_anchor=”” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” status=”published” publish_date=”” class=”” id=”” spacing_medium=”” margin_top_medium=”” margin_bottom_medium=”” spacing_small=”” margin_top_small=”” margin_bottom_small=”” margin_top=”” margin_bottom=”” padding_dimensions_medium=”” padding_top_medium=”” padding_right_medium=”” padding_bottom_medium=”” padding_left_medium=”” padding_dimensions_small=”” padding_top_small=”” padding_right_small=”” padding_bottom_small=”” padding_left_small=”” padding_top=”” padding_right=”” padding_bottom=”” padding_left=”” link_color=”” link_hover_color=”” border_sizes=”” border_sizes_top=”” border_sizes_right=”” border_sizes_bottom=”” border_sizes_left=”” border_color=”” border_style=”solid” box_shadow=”no” box_shadow_vertical=”” box_shadow_horizontal=”” box_shadow_blur=”0″ box_shadow_spread=”0″ box_shadow_color=”” box_shadow_style=”” z_index=”” overflow=”” gradient_start_color=”” gradient_end_color=”” gradient_start_position=”0″ gradient_end_position=”100″ gradient_type=”linear” radial_direction=”center center” linear_angle=”180″ background_color=”” background_image=”” skip_lazy_load=”” background_position=”center center” background_repeat=”no-repeat” fade=”no” background_parallax=”none” enable_mobile=”no” parallax_speed=”0.3″ background_blend_mode=”none” video_mp4=”” video_webm=”” video_ogv=”” video_url=”” video_aspect_ratio=”16:9″ video_loop=”yes” video_mute=”yes” video_preview_image=”” render_logics=”” absolute=”off” absolute_devices=”small,medium,large” sticky=”off” sticky_devices=”small-visibility,medium-visibility,large-visibility” sticky_background_color=”” sticky_height=”” sticky_offset=”” sticky_transition_offset=”0″ scroll_offset=”0″ animation_type=”” animation_direction=”left” animation_speed=”0.3″ animation_offset=”” filter_hue=”0″ filter_saturation=”100″ filter_brightness=”100″ filter_contrast=”100″ filter_invert=”0″ filter_sepia=”0″ filter_opacity=”100″ filter_blur=”0″ filter_hue_hover=”0″ filter_saturation_hover=”100″ filter_brightness_hover=”100″ filter_contrast_hover=”100″ filter_invert_hover=”0″ filter_sepia_hover=”0″ filter_opacity_hover=”100″ filter_blur_hover=”0″][fusion_builder_row][fusion_builder_column type=”1_1″ layout=”1_1″ align_self=”auto” content_layout=”column” align_content=”flex-start” valign_content=”flex-start” content_wrap=”wrap” spacing=”” center_content=”no” link=”” target=”_self” min_height=”” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” sticky_display=”normal,sticky” class=”” id=”” type_medium=”” type_small=”” order_medium=”0″ order_small=”0″ dimension_spacing_medium=”” dimension_spacing_small=”” dimension_spacing=”” dimension_margin_medium=”” dimension_margin_small=”” margin_top=”” margin_bottom=”” padding_medium=”” padding_small=”” padding_top=”” padding_right=”” padding_bottom=”” padding_left=”” hover_type=”none” border_sizes=”” border_color=”” border_style=”solid” border_radius=”” box_shadow=”no” dimension_box_shadow=”” box_shadow_blur=”0″ box_shadow_spread=”0″ box_shadow_color=”” box_shadow_style=”” background_type=”single” gradient_start_color=”” gradient_end_color=”” gradient_start_position=”0″ gradient_end_position=”100″ gradient_type=”linear” radial_direction=”center center” linear_angle=”180″ background_color=”” background_image=”” background_image_id=”” background_position=”left top” background_repeat=”no-repeat” background_blend_mode=”none” render_logics=”” filter_type=”regular” filter_hue=”0″ filter_saturation=”100″ filter_brightness=”100″ filter_contrast=”100″ filter_invert=”0″ filter_sepia=”0″ filter_opacity=”100″ filter_blur=”0″ filter_hue_hover=”0″ filter_saturation_hover=”100″ filter_brightness_hover=”100″ filter_contrast_hover=”100″ filter_invert_hover=”0″ filter_sepia_hover=”0″ filter_opacity_hover=”100″ filter_blur_hover=”0″ animation_type=”” animation_direction=”left” animation_speed=”0.3″ animation_offset=”” last=”true” border_position=”all” first=”true”][fusion_separator style_type=”shadow” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” sticky_display=”normal,sticky” class=”” id=”” flex_grow=”0″ top_margin=”” bottom_margin=”” width=”” alignment=”center” border_size=”” sep_color=”” icon=”” icon_size=”” icon_color=”” icon_circle=”” icon_circle_color=”” /][/fusion_builder_column][/fusion_builder_row][/fusion_builder_container][fusion_builder_container type=”flex” hundred_percent=”no” hundred_percent_height=”no” hundred_percent_height_scroll=”no” align_content=”stretch” flex_align_items=”flex-start” flex_justify_content=”flex-start” hundred_percent_height_center_content=”yes” equal_height_columns=”no” container_tag=”div” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” status=”published” border_style=”solid” box_shadow=”no” box_shadow_blur=”0″ box_shadow_spread=”0″ gradient_start_position=”0″ gradient_end_position=”100″ gradient_type=”linear” radial_direction=”center center” linear_angle=”180″ background_position=”center center” background_repeat=”no-repeat” fade=”no” background_parallax=”none” enable_mobile=”no” parallax_speed=”0.3″ background_blend_mode=”none” video_aspect_ratio=”16:9″ video_loop=”yes” video_mute=”yes” absolute=”off” absolute_devices=”small,medium,large” sticky=”off” sticky_devices=”small-visibility,medium-visibility,large-visibility” sticky_transition_offset=”0″ scroll_offset=”0″ animation_direction=”left” animation_speed=”0.3″ filter_hue=”0″ filter_saturation=”100″ filter_brightness=”100″ filter_contrast=”100″ filter_invert=”0″ filter_sepia=”0″ filter_opacity=”100″ filter_blur=”0″ filter_hue_hover=”0″ filter_saturation_hover=”100″ filter_brightness_hover=”100″ filter_contrast_hover=”100″ filter_invert_hover=”0″ filter_sepia_hover=”0″ filter_opacity_hover=”100″ filter_blur_hover=”0″][fusion_builder_row][fusion_builder_column type=”1_1″ layout=”1_1″ align_self=”auto” content_layout=”column” align_content=”flex-start” valign_content=”flex-start” content_wrap=”wrap” spacing=”” center_content=”no” link=”” target=”_self” min_height=”” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” sticky_display=”normal,sticky” class=”” id=”” type_medium=”” type_small=”” order_medium=”0″ order_small=”0″ dimension_spacing_medium=”” dimension_spacing_small=”” dimension_spacing=”” dimension_margin_medium=”” dimension_margin_small=”” margin_top=”” margin_bottom=”” padding_medium=”” padding_small=”” padding_top=”” padding_right=”” padding_bottom=”” padding_left=”” hover_type=”none” border_sizes=”” border_color=”” border_style=”solid” border_radius=”” box_shadow=”no” dimension_box_shadow=”” box_shadow_blur=”0″ box_shadow_spread=”0″ box_shadow_color=”” box_shadow_style=”” background_type=”single” gradient_start_color=”” gradient_end_color=”” gradient_start_position=”0″ gradient_end_position=”100″ gradient_type=”linear” radial_direction=”center center” linear_angle=”180″ background_color=”” background_image=”” background_image_id=”” background_position=”left top” background_repeat=”no-repeat” background_blend_mode=”none” render_logics=”” filter_type=”regular” filter_hue=”0″ filter_saturation=”100″ filter_brightness=”100″ filter_contrast=”100″ filter_invert=”0″ filter_sepia=”0″ filter_opacity=”100″ filter_blur=”0″ filter_hue_hover=”0″ filter_saturation_hover=”100″ filter_brightness_hover=”100″ filter_contrast_hover=”100″ filter_invert_hover=”0″ filter_sepia_hover=”0″ filter_opacity_hover=”100″ filter_blur_hover=”0″ animation_type=”” animation_direction=”left” animation_speed=”0.3″ animation_offset=”” last=”true” border_position=”all” first=”true”][fusion_text columns=”” column_min_width=”” column_spacing=”” rule_style=”default” rule_size=”” rule_color=”” content_alignment_medium=”” content_alignment_small=”” content_alignment=”” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” sticky_display=”normal,sticky” class=”” id=”” margin_top=”” margin_right=”” margin_bottom=”” margin_left=”” font_size=”” fusion_font_family_text_font=”” fusion_font_variant_text_font=”” line_height=”” letter_spacing=”” text_color=”” animation_type=”” animation_direction=”left” animation_speed=”0.3″ animation_offset=””]
Features of Apache Spark
Apache Spark has following features.
- Speed − Spark helps to run an application in Hadoop cluster, up to 100 times faster in memory, and 10 times faster when running on disk. This is possible by reducing number of read/write operations to disk. It stores the intermediate processing data in memory.
- Supports multiple languages − Spark provides built-in APIs in Java, Scala, or Python. Therefore, you can write applications in different languages. Spark comes up with 80 high-level operators for interactive querying.
- Advanced Analytics − Spark not only supports ‘Map’ and ‘reduce’. It also supports SQL queries, Streaming data, Machine learning (ML), and Graph algorithms.
[/fusion_text][/fusion_builder_column][/fusion_builder_row][/fusion_builder_container][fusion_builder_container type=”flex” hundred_percent=”no” hundred_percent_height=”no” min_height_medium=”” min_height_small=”” min_height=”” hundred_percent_height_scroll=”no” align_content=”stretch” flex_align_items=”flex-start” flex_justify_content=”flex-start” flex_column_spacing=”” hundred_percent_height_center_content=”yes” equal_height_columns=”no” container_tag=”div” menu_anchor=”” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” status=”published” publish_date=”” class=”” id=”” spacing_medium=”” margin_top_medium=”” margin_bottom_medium=”” spacing_small=”” margin_top_small=”” margin_bottom_small=”” margin_top=”” margin_bottom=”” padding_dimensions_medium=”” padding_top_medium=”” padding_right_medium=”” padding_bottom_medium=”” padding_left_medium=”” padding_dimensions_small=”” padding_top_small=”” padding_right_small=”” padding_bottom_small=”” padding_left_small=”” padding_top=”” padding_right=”” padding_bottom=”” padding_left=”” link_color=”” link_hover_color=”” border_sizes=”” border_sizes_top=”” border_sizes_right=”” border_sizes_bottom=”” border_sizes_left=”” border_color=”” border_style=”solid” box_shadow=”no” box_shadow_vertical=”” box_shadow_horizontal=”” box_shadow_blur=”0″ box_shadow_spread=”0″ box_shadow_color=”” box_shadow_style=”” z_index=”” overflow=”” gradient_start_color=”” gradient_end_color=”” gradient_start_position=”0″ gradient_end_position=”100″ gradient_type=”linear” radial_direction=”center center” linear_angle=”180″ background_color=”” background_image=”” skip_lazy_load=”” background_position=”center center” background_repeat=”no-repeat” fade=”no” background_parallax=”none” enable_mobile=”no” parallax_speed=”0.3″ background_blend_mode=”none” video_mp4=”” video_webm=”” video_ogv=”” video_url=”” video_aspect_ratio=”16:9″ video_loop=”yes” video_mute=”yes” video_preview_image=”” render_logics=”” absolute=”off” absolute_devices=”small,medium,large” sticky=”off” sticky_devices=”small-visibility,medium-visibility,large-visibility” sticky_background_color=”” sticky_height=”” sticky_offset=”” sticky_transition_offset=”0″ scroll_offset=”0″ animation_type=”” animation_direction=”left” animation_speed=”0.3″ animation_offset=”” filter_hue=”0″ filter_saturation=”100″ filter_brightness=”100″ filter_contrast=”100″ filter_invert=”0″ filter_sepia=”0″ filter_opacity=”100″ filter_blur=”0″ filter_hue_hover=”0″ filter_saturation_hover=”100″ filter_brightness_hover=”100″ filter_contrast_hover=”100″ filter_invert_hover=”0″ filter_sepia_hover=”0″ filter_opacity_hover=”100″ filter_blur_hover=”0″][fusion_builder_row][fusion_builder_column type=”1_1″ layout=”1_1″ align_self=”auto” content_layout=”column” align_content=”flex-start” valign_content=”flex-start” content_wrap=”wrap” spacing=”” center_content=”no” link=”” target=”_self” min_height=”” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” sticky_display=”normal,sticky” class=”” id=”” type_medium=”” type_small=”” order_medium=”0″ order_small=”0″ dimension_spacing_medium=”” dimension_spacing_small=”” dimension_spacing=”” dimension_margin_medium=”” dimension_margin_small=”” margin_top=”” margin_bottom=”” padding_medium=”” padding_small=”” padding_top=”” padding_right=”” padding_bottom=”” padding_left=”” hover_type=”none” border_sizes=”” border_color=”” border_style=”solid” border_radius=”” box_shadow=”no” dimension_box_shadow=”” box_shadow_blur=”0″ box_shadow_spread=”0″ box_shadow_color=”” box_shadow_style=”” background_type=”single” gradient_start_color=”” gradient_end_color=”” gradient_start_position=”0″ gradient_end_position=”100″ gradient_type=”linear” radial_direction=”center center” linear_angle=”180″ background_color=”” background_image=”” background_image_id=”” background_position=”left top” background_repeat=”no-repeat” background_blend_mode=”none” render_logics=”” filter_type=”regular” filter_hue=”0″ filter_saturation=”100″ filter_brightness=”100″ filter_contrast=”100″ filter_invert=”0″ filter_sepia=”0″ filter_opacity=”100″ filter_blur=”0″ filter_hue_hover=”0″ filter_saturation_hover=”100″ filter_brightness_hover=”100″ filter_contrast_hover=”100″ filter_invert_hover=”0″ filter_sepia_hover=”0″ filter_opacity_hover=”100″ filter_blur_hover=”0″ animation_type=”” animation_direction=”left” animation_speed=”0.3″ animation_offset=”” last=”true” border_position=”all” first=”true”][fusion_separator style_type=”shadow” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” sticky_display=”normal,sticky” class=”” id=”” flex_grow=”0″ top_margin=”” bottom_margin=”” width=”” alignment=”center” border_size=”” sep_color=”” icon=”” icon_size=”” icon_color=”” icon_circle=”” icon_circle_color=”” /][/fusion_builder_column][/fusion_builder_row][/fusion_builder_container][fusion_builder_container type=”flex” hundred_percent=”no” hundred_percent_height=”no” hundred_percent_height_scroll=”no” align_content=”stretch” flex_align_items=”flex-start” flex_justify_content=”flex-start” hundred_percent_height_center_content=”yes” equal_height_columns=”no” container_tag=”div” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” status=”published” border_style=”solid” box_shadow=”no” box_shadow_blur=”0″ box_shadow_spread=”0″ gradient_start_position=”0″ gradient_end_position=”100″ gradient_type=”linear” radial_direction=”center center” linear_angle=”180″ background_position=”center center” background_repeat=”no-repeat” fade=”no” background_parallax=”none” enable_mobile=”no” parallax_speed=”0.3″ background_blend_mode=”none” video_aspect_ratio=”16:9″ video_loop=”yes” video_mute=”yes” absolute=”off” absolute_devices=”small,medium,large” sticky=”off” sticky_devices=”small-visibility,medium-visibility,large-visibility” sticky_transition_offset=”0″ scroll_offset=”0″ animation_direction=”left” animation_speed=”0.3″ filter_hue=”0″ filter_saturation=”100″ filter_brightness=”100″ filter_contrast=”100″ filter_invert=”0″ filter_sepia=”0″ filter_opacity=”100″ filter_blur=”0″ filter_hue_hover=”0″ filter_saturation_hover=”100″ filter_brightness_hover=”100″ filter_contrast_hover=”100″ filter_invert_hover=”0″ filter_sepia_hover=”0″ filter_opacity_hover=”100″ filter_blur_hover=”0″][fusion_builder_row][fusion_builder_column type=”1_1″ layout=”1_1″ align_self=”auto” content_layout=”column” align_content=”flex-start” valign_content=”flex-start” content_wrap=”wrap” spacing=”” center_content=”no” link=”” target=”_self” min_height=”” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” sticky_display=”normal,sticky” class=”” id=”” type_medium=”” type_small=”” order_medium=”0″ order_small=”0″ dimension_spacing_medium=”” dimension_spacing_small=”” dimension_spacing=”” dimension_margin_medium=”” dimension_margin_small=”” margin_top=”” margin_bottom=”” padding_medium=”” padding_small=”” padding_top=”” padding_right=”” padding_bottom=”” padding_left=”” hover_type=”none” border_sizes=”” border_color=”” border_style=”solid” border_radius=”” box_shadow=”no” dimension_box_shadow=”” box_shadow_blur=”0″ box_shadow_spread=”0″ box_shadow_color=”” box_shadow_style=”” background_type=”single” gradient_start_color=”” gradient_end_color=”” gradient_start_position=”0″ gradient_end_position=”100″ gradient_type=”linear” radial_direction=”center center” linear_angle=”180″ background_color=”” background_image=”” background_image_id=”” background_position=”left top” background_repeat=”no-repeat” background_blend_mode=”none” render_logics=”” filter_type=”regular” filter_hue=”0″ filter_saturation=”100″ filter_brightness=”100″ filter_contrast=”100″ filter_invert=”0″ filter_sepia=”0″ filter_opacity=”100″ filter_blur=”0″ filter_hue_hover=”0″ filter_saturation_hover=”100″ filter_brightness_hover=”100″ filter_contrast_hover=”100″ filter_invert_hover=”0″ filter_sepia_hover=”0″ filter_opacity_hover=”100″ filter_blur_hover=”0″ animation_type=”” animation_direction=”left” animation_speed=”0.3″ animation_offset=”” last=”true” border_position=”all” first=”true”][fusion_text columns=”” column_min_width=”” column_spacing=”” rule_style=”default” rule_size=”” rule_color=”” content_alignment_medium=”” content_alignment_small=”” content_alignment=”” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” sticky_display=”normal,sticky” class=”” id=”” margin_top=”” margin_right=”” margin_bottom=”” margin_left=”” font_size=”” fusion_font_family_text_font=”” fusion_font_variant_text_font=”” line_height=”” letter_spacing=”” text_color=”” animation_type=”” animation_direction=”left” animation_speed=”0.3″ animation_offset=””]
Benefits of Apache Spark
Speed
Engineered from the bottom-up for performance, Spark can be 100x faster than Hadoop for large scale data processing by exploiting in memory computing and other optimizations. Spark is also fast when data is stored on disk, and currently holds the world record for large-scale on-disk sorting.
Ease of Use
Spark has easy-to-use APIs for operating on large datasets. This includes a collection of over 100 operators for transforming data and familiar data frame APIs for manipulating semi-structured data.
A Unified Engine
Spark comes packaged with higher-level libraries, including support for SQL queries, streaming data, machine learning and graph processing. These standard libraries increase developer productivity and can be seamlessly combined to create complex workflows.
[/fusion_text][/fusion_builder_column][/fusion_builder_row][/fusion_builder_container][fusion_builder_container type=”flex” hundred_percent=”no” hundred_percent_height=”no” min_height_medium=”” min_height_small=”” min_height=”” hundred_percent_height_scroll=”no” align_content=”stretch” flex_align_items=”flex-start” flex_justify_content=”flex-start” flex_column_spacing=”” hundred_percent_height_center_content=”yes” equal_height_columns=”no” container_tag=”div” menu_anchor=”” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” status=”published” publish_date=”” class=”” id=”” spacing_medium=”” margin_top_medium=”” margin_bottom_medium=”” spacing_small=”” margin_top_small=”” margin_bottom_small=”” margin_top=”” margin_bottom=”” padding_dimensions_medium=”” padding_top_medium=”” padding_right_medium=”” padding_bottom_medium=”” padding_left_medium=”” padding_dimensions_small=”” padding_top_small=”” padding_right_small=”” padding_bottom_small=”” padding_left_small=”” padding_top=”” padding_right=”” padding_bottom=”” padding_left=”” link_color=”” link_hover_color=”” border_sizes=”” border_sizes_top=”” border_sizes_right=”” border_sizes_bottom=”” border_sizes_left=”” border_color=”” border_style=”solid” box_shadow=”no” box_shadow_vertical=”” box_shadow_horizontal=”” box_shadow_blur=”0″ box_shadow_spread=”0″ box_shadow_color=”” box_shadow_style=”” z_index=”” overflow=”” gradient_start_color=”” gradient_end_color=”” gradient_start_position=”0″ gradient_end_position=”100″ gradient_type=”linear” radial_direction=”center center” linear_angle=”180″ background_color=”” background_image=”” skip_lazy_load=”” background_position=”center center” background_repeat=”no-repeat” fade=”no” background_parallax=”none” enable_mobile=”no” parallax_speed=”0.3″ background_blend_mode=”none” video_mp4=”” video_webm=”” video_ogv=”” video_url=”” video_aspect_ratio=”16:9″ video_loop=”yes” video_mute=”yes” video_preview_image=”” render_logics=”” absolute=”off” absolute_devices=”small,medium,large” sticky=”off” sticky_devices=”small-visibility,medium-visibility,large-visibility” sticky_background_color=”” sticky_height=”” sticky_offset=”” sticky_transition_offset=”0″ scroll_offset=”0″ animation_type=”” animation_direction=”left” animation_speed=”0.3″ animation_offset=”” filter_hue=”0″ filter_saturation=”100″ filter_brightness=”100″ filter_contrast=”100″ filter_invert=”0″ filter_sepia=”0″ filter_opacity=”100″ filter_blur=”0″ filter_hue_hover=”0″ filter_saturation_hover=”100″ filter_brightness_hover=”100″ filter_contrast_hover=”100″ filter_invert_hover=”0″ filter_sepia_hover=”0″ filter_opacity_hover=”100″ filter_blur_hover=”0″][fusion_builder_row][fusion_builder_column type=”1_1″ layout=”1_1″ align_self=”auto” content_layout=”column” align_content=”flex-start” valign_content=”flex-start” content_wrap=”wrap” spacing=”” center_content=”no” link=”” target=”_self” min_height=”” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” sticky_display=”normal,sticky” class=”” id=”” type_medium=”” type_small=”” order_medium=”0″ order_small=”0″ dimension_spacing_medium=”” dimension_spacing_small=”” dimension_spacing=”” dimension_margin_medium=”” dimension_margin_small=”” margin_top=”” margin_bottom=”” padding_medium=”” padding_small=”” padding_top=”” padding_right=”” padding_bottom=”” padding_left=”” hover_type=”none” border_sizes=”” border_color=”” border_style=”solid” border_radius=”” box_shadow=”no” dimension_box_shadow=”” box_shadow_blur=”0″ box_shadow_spread=”0″ box_shadow_color=”” box_shadow_style=”” background_type=”single” gradient_start_color=”” gradient_end_color=”” gradient_start_position=”0″ gradient_end_position=”100″ gradient_type=”linear” radial_direction=”center center” linear_angle=”180″ background_color=”” background_image=”” background_image_id=”” background_position=”left top” background_repeat=”no-repeat” background_blend_mode=”none” render_logics=”” filter_type=”regular” filter_hue=”0″ filter_saturation=”100″ filter_brightness=”100″ filter_contrast=”100″ filter_invert=”0″ filter_sepia=”0″ filter_opacity=”100″ filter_blur=”0″ filter_hue_hover=”0″ filter_saturation_hover=”100″ filter_brightness_hover=”100″ filter_contrast_hover=”100″ filter_invert_hover=”0″ filter_sepia_hover=”0″ filter_opacity_hover=”100″ filter_blur_hover=”0″ animation_type=”” animation_direction=”left” animation_speed=”0.3″ animation_offset=”” last=”true” border_position=”all” first=”true”][fusion_separator style_type=”shadow” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” sticky_display=”normal,sticky” class=”” id=”” flex_grow=”0″ top_margin=”” bottom_margin=”” width=”” alignment=”center” border_size=”” sep_color=”” icon=”” icon_size=”” icon_color=”” icon_circle=”” icon_circle_color=”” /][/fusion_builder_column][/fusion_builder_row][/fusion_builder_container][fusion_builder_container type=”flex” hundred_percent=”no” hundred_percent_height=”no” hundred_percent_height_scroll=”no” align_content=”stretch” flex_align_items=”flex-start” flex_justify_content=”flex-start” hundred_percent_height_center_content=”yes” equal_height_columns=”no” container_tag=”div” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” status=”published” border_style=”solid” box_shadow=”no” box_shadow_blur=”0″ box_shadow_spread=”0″ gradient_start_position=”0″ gradient_end_position=”100″ gradient_type=”linear” radial_direction=”center center” linear_angle=”180″ background_position=”center center” background_repeat=”no-repeat” fade=”no” background_parallax=”none” enable_mobile=”no” parallax_speed=”0.3″ background_blend_mode=”none” video_aspect_ratio=”16:9″ video_loop=”yes” video_mute=”yes” absolute=”off” absolute_devices=”small,medium,large” sticky=”off” sticky_devices=”small-visibility,medium-visibility,large-visibility” sticky_transition_offset=”0″ scroll_offset=”0″ animation_direction=”left” animation_speed=”0.3″ filter_hue=”0″ filter_saturation=”100″ filter_brightness=”100″ filter_contrast=”100″ filter_invert=”0″ filter_sepia=”0″ filter_opacity=”100″ filter_blur=”0″ filter_hue_hover=”0″ filter_saturation_hover=”100″ filter_brightness_hover=”100″ filter_contrast_hover=”100″ filter_invert_hover=”0″ filter_sepia_hover=”0″ filter_opacity_hover=”100″ filter_blur_hover=”0″][fusion_builder_row][fusion_builder_column type=”1_1″ layout=”1_1″ align_self=”auto” content_layout=”column” align_content=”flex-start” valign_content=”flex-start” content_wrap=”wrap” spacing=”” center_content=”no” link=”” target=”_self” min_height=”” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” sticky_display=”normal,sticky” class=”” id=”” type_medium=”” type_small=”” order_medium=”0″ order_small=”0″ dimension_spacing_medium=”” dimension_spacing_small=”” dimension_spacing=”” dimension_margin_medium=”” dimension_margin_small=”” margin_top=”” margin_bottom=”” padding_medium=”” padding_small=”” padding_top=”” padding_right=”” padding_bottom=”” padding_left=”” hover_type=”none” border_sizes=”” border_color=”” border_style=”solid” border_radius=”” box_shadow=”no” dimension_box_shadow=”” box_shadow_blur=”0″ box_shadow_spread=”0″ box_shadow_color=”” box_shadow_style=”” background_type=”single” gradient_start_color=”” gradient_end_color=”” gradient_start_position=”0″ gradient_end_position=”100″ gradient_type=”linear” radial_direction=”center center” linear_angle=”180″ background_color=”” background_image=”” background_image_id=”” background_position=”left top” background_repeat=”no-repeat” background_blend_mode=”none” render_logics=”” filter_type=”regular” filter_hue=”0″ filter_saturation=”100″ filter_brightness=”100″ filter_contrast=”100″ filter_invert=”0″ filter_sepia=”0″ filter_opacity=”100″ filter_blur=”0″ filter_hue_hover=”0″ filter_saturation_hover=”100″ filter_brightness_hover=”100″ filter_contrast_hover=”100″ filter_invert_hover=”0″ filter_sepia_hover=”0″ filter_opacity_hover=”100″ filter_blur_hover=”0″ animation_type=”” animation_direction=”left” animation_speed=”0.3″ animation_offset=”” last=”true” border_position=”all” first=”true”][fusion_text columns=”” column_min_width=”” column_spacing=”” rule_style=”default” rule_size=”” rule_color=”” content_alignment_medium=”” content_alignment_small=”” content_alignment=”” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” sticky_display=”normal,sticky” class=”” id=”” margin_top=”” margin_right=”” margin_bottom=”” margin_left=”” font_size=”” fusion_font_family_text_font=”” fusion_font_variant_text_font=”” line_height=”” letter_spacing=”” text_color=”” animation_type=”” animation_direction=”left” animation_speed=”0.3″ animation_offset=””]
Conclusion
To sum up, Spark helps to simplify the challenging and computationally intensive task of processing high volumes of real-time or archived data, both structured and unstructured, seamlessly integrating relevant complex capabilities such as machine learning and graph algorithms. Spark brings Big Data processing to the masses. Check it out!
[/fusion_text][/fusion_builder_column][/fusion_builder_row][/fusion_builder_container][fusion_builder_container type=”flex” hundred_percent=”no” hundred_percent_height=”no” min_height_medium=”” min_height_small=”” min_height=”” hundred_percent_height_scroll=”no” align_content=”stretch” flex_align_items=”flex-start” flex_justify_content=”flex-start” flex_column_spacing=”” hundred_percent_height_center_content=”yes” equal_height_columns=”no” container_tag=”div” menu_anchor=”” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” status=”published” publish_date=”” class=”” id=”” spacing_medium=”” margin_top_medium=”” margin_bottom_medium=”” spacing_small=”” margin_top_small=”” margin_bottom_small=”” margin_top=”” margin_bottom=”” padding_dimensions_medium=”” padding_top_medium=”” padding_right_medium=”” padding_bottom_medium=”” padding_left_medium=”” padding_dimensions_small=”” padding_top_small=”” padding_right_small=”” padding_bottom_small=”” padding_left_small=”” padding_top=”” padding_right=”” padding_bottom=”” padding_left=”” link_color=”” link_hover_color=”” border_sizes=”” border_sizes_top=”” border_sizes_right=”” border_sizes_bottom=”” border_sizes_left=”” border_color=”” border_style=”solid” box_shadow=”no” box_shadow_vertical=”” box_shadow_horizontal=”” box_shadow_blur=”0″ box_shadow_spread=”0″ box_shadow_color=”” box_shadow_style=”” z_index=”” overflow=”” gradient_start_color=”” gradient_end_color=”” gradient_start_position=”0″ gradient_end_position=”100″ gradient_type=”linear” radial_direction=”center center” linear_angle=”180″ background_color=”” background_image=”” skip_lazy_load=”” background_position=”center center” background_repeat=”no-repeat” fade=”no” background_parallax=”none” enable_mobile=”no” parallax_speed=”0.3″ background_blend_mode=”none” video_mp4=”” video_webm=”” video_ogv=”” video_url=”” video_aspect_ratio=”16:9″ video_loop=”yes” video_mute=”yes” video_preview_image=”” render_logics=”” absolute=”off” absolute_devices=”small,medium,large” sticky=”off” sticky_devices=”small-visibility,medium-visibility,large-visibility” sticky_background_color=”” sticky_height=”” sticky_offset=”” sticky_transition_offset=”0″ scroll_offset=”0″ animation_type=”” animation_direction=”left” animation_speed=”0.3″ animation_offset=”” filter_hue=”0″ filter_saturation=”100″ filter_brightness=”100″ filter_contrast=”100″ filter_invert=”0″ filter_sepia=”0″ filter_opacity=”100″ filter_blur=”0″ filter_hue_hover=”0″ filter_saturation_hover=”100″ filter_brightness_hover=”100″ filter_contrast_hover=”100″ filter_invert_hover=”0″ filter_sepia_hover=”0″ filter_opacity_hover=”100″ filter_blur_hover=”0″][fusion_builder_row][fusion_builder_column type=”1_1″ layout=”1_1″ align_self=”auto” content_layout=”column” align_content=”flex-start” valign_content=”flex-start” content_wrap=”wrap” spacing=”” center_content=”no” link=”” target=”_self” min_height=”” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” sticky_display=”normal,sticky” class=”” id=”” type_medium=”” type_small=”” order_medium=”0″ order_small=”0″ dimension_spacing_medium=”” dimension_spacing_small=”” dimension_spacing=”” dimension_margin_medium=”” dimension_margin_small=”” margin_top=”” margin_bottom=”” padding_medium=”” padding_small=”” padding_top=”” padding_right=”” padding_bottom=”” padding_left=”” hover_type=”none” border_sizes=”” border_color=”” border_style=”solid” border_radius=”” box_shadow=”no” dimension_box_shadow=”” box_shadow_blur=”0″ box_shadow_spread=”0″ box_shadow_color=”” box_shadow_style=”” background_type=”single” gradient_start_color=”” gradient_end_color=”” gradient_start_position=”0″ gradient_end_position=”100″ gradient_type=”linear” radial_direction=”center center” linear_angle=”180″ background_color=”” background_image=”” background_image_id=”” background_position=”left top” background_repeat=”no-repeat” background_blend_mode=”none” render_logics=”” filter_type=”regular” filter_hue=”0″ filter_saturation=”100″ filter_brightness=”100″ filter_contrast=”100″ filter_invert=”0″ filter_sepia=”0″ filter_opacity=”100″ filter_blur=”0″ filter_hue_hover=”0″ filter_saturation_hover=”100″ filter_brightness_hover=”100″ filter_contrast_hover=”100″ filter_invert_hover=”0″ filter_sepia_hover=”0″ filter_opacity_hover=”100″ filter_blur_hover=”0″ animation_type=”” animation_direction=”left” animation_speed=”0.3″ animation_offset=”” last=”true” border_position=”all” first=”true”][fusion_separator style_type=”shadow” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” sticky_display=”normal,sticky” class=”” id=”” flex_grow=”0″ top_margin=”” bottom_margin=”” width=”” alignment=”center” border_size=”” sep_color=”” icon=”” icon_size=”” icon_color=”” icon_circle=”” icon_circle_color=”” /][/fusion_builder_column][/fusion_builder_row][/fusion_builder_container][fusion_builder_container type=”flex” hundred_percent=”no” hundred_percent_height=”no” min_height_medium=”” min_height_small=”” min_height=”” hundred_percent_height_scroll=”no” align_content=”stretch” flex_align_items=”flex-start” flex_justify_content=”flex-start” flex_column_spacing=”” hundred_percent_height_center_content=”yes” equal_height_columns=”no” container_tag=”div” menu_anchor=”” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” status=”published” publish_date=”” class=”” id=”” spacing_medium=”” margin_top_medium=”” margin_bottom_medium=”” spacing_small=”” margin_top_small=”” margin_bottom_small=”” margin_top=”” margin_bottom=”” padding_dimensions_medium=”” padding_top_medium=”” padding_right_medium=”” padding_bottom_medium=”” padding_left_medium=”” padding_dimensions_small=”” padding_top_small=”” padding_right_small=”” padding_bottom_small=”” padding_left_small=”” padding_top=”” padding_right=”” padding_bottom=”” padding_left=”” link_color=”” link_hover_color=”” border_sizes=”” border_sizes_top=”” border_sizes_right=”” border_sizes_bottom=”” border_sizes_left=”” border_color=”” border_style=”solid” box_shadow=”no” box_shadow_vertical=”” box_shadow_horizontal=”” box_shadow_blur=”0″ box_shadow_spread=”0″ box_shadow_color=”” box_shadow_style=”” z_index=”” overflow=”” gradient_start_color=”” gradient_end_color=”” gradient_start_position=”0″ gradient_end_position=”100″ gradient_type=”linear” radial_direction=”center center” linear_angle=”180″ background_color=”” background_image=”” skip_lazy_load=”” background_position=”center center” background_repeat=”no-repeat” fade=”no” background_parallax=”none” enable_mobile=”no” parallax_speed=”0.3″ background_blend_mode=”none” video_mp4=”” video_webm=”” video_ogv=”” video_url=”” video_aspect_ratio=”16:9″ video_loop=”yes” video_mute=”yes” video_preview_image=”” render_logics=”” absolute=”off” absolute_devices=”small,medium,large” sticky=”off” sticky_devices=”small-visibility,medium-visibility,large-visibility” sticky_background_color=”” sticky_height=”” sticky_offset=”” sticky_transition_offset=”0″ scroll_offset=”0″ animation_type=”” animation_direction=”left” animation_speed=”0.3″ animation_offset=”” filter_hue=”0″ filter_saturation=”100″ filter_brightness=”100″ filter_contrast=”100″ filter_invert=”0″ filter_sepia=”0″ filter_opacity=”100″ filter_blur=”0″ filter_hue_hover=”0″ filter_saturation_hover=”100″ filter_brightness_hover=”100″ filter_contrast_hover=”100″ filter_invert_hover=”0″ filter_sepia_hover=”0″ filter_opacity_hover=”100″ filter_blur_hover=”0″][fusion_builder_row][fusion_builder_column type=”1_1″ layout=”1_1″ align_self=”auto” content_layout=”column” align_content=”flex-start” valign_content=”flex-start” content_wrap=”wrap” spacing=”” center_content=”no” link=”” target=”_self” min_height=”” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” sticky_display=”normal,sticky” class=”” id=”” type_medium=”” type_small=”” order_medium=”0″ order_small=”0″ dimension_spacing_medium=”” dimension_spacing_small=”” dimension_spacing=”” dimension_margin_medium=”” dimension_margin_small=”” margin_top=”” margin_bottom=”” padding_medium=”” padding_small=”” padding_top=”” padding_right=”” padding_bottom=”” padding_left=”” hover_type=”none” border_sizes=”” border_color=”” border_style=”solid” border_radius=”” box_shadow=”no” dimension_box_shadow=”” box_shadow_blur=”0″ box_shadow_spread=”0″ box_shadow_color=”” box_shadow_style=”” background_type=”single” gradient_start_color=”” gradient_end_color=”” gradient_start_position=”0″ gradient_end_position=”100″ gradient_type=”linear” radial_direction=”center center” linear_angle=”180″ background_color=”” background_image=”” background_image_id=”” background_position=”left top” background_repeat=”no-repeat” background_blend_mode=”none” render_logics=”” filter_type=”regular” filter_hue=”0″ filter_saturation=”100″ filter_brightness=”100″ filter_contrast=”100″ filter_invert=”0″ filter_sepia=”0″ filter_opacity=”100″ filter_blur=”0″ filter_hue_hover=”0″ filter_saturation_hover=”100″ filter_brightness_hover=”100″ filter_contrast_hover=”100″ filter_invert_hover=”0″ filter_sepia_hover=”0″ filter_opacity_hover=”100″ filter_blur_hover=”0″ animation_type=”” animation_direction=”left” animation_speed=”0.3″ animation_offset=”” last=”true” border_position=”all” first=”true”][fusion_images picture_size=”fixed” hover_type=”none” autoplay=”yes” columns=”6″ column_spacing=”13″ scroll_items=”” show_nav=”no” mouse_scroll=”no” border=”yes” lightbox=”yes” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” class=”” id=””][fusion_image image=”https://ismuniv.com/wp-content/uploads/2018/11/Imagers_0942.jpg” image_id=”2208″ link=”” linktarget=”_self” alt=”” /][fusion_image image=”https://ismuniv.com/wp-content/uploads/2018/11/Imagers_2651.jpg” image_id=”2221″ link=”” linktarget=”_self” alt=”” /][fusion_image image=”https://ismuniv.com/wp-content/uploads/2018/11/Imagers_1422.jpg” image_id=”2210″ link=”” linktarget=”_self” alt=”” /][fusion_image image=”https://ismuniv.com/wp-content/uploads/2018/11/Imagers_1822.jpg” image_id=”2215″ link=”” linktarget=”_self” alt=”” /][fusion_image image=”https://ismuniv.com/wp-content/uploads/2018/11/Imagers_0502.jpg” image_id=”2203″ link=”” linktarget=”_self” alt=”” /][fusion_image image=”https://ismuniv.com/wp-content/uploads/2018/11/Imagers_0772.jpg” image_id=”2205″ link=”” linktarget=”_self” alt=”” /][fusion_image image=”https://ismuniv.com/wp-content/uploads/2018/11/Imagers_1752.jpg” image_id=”2213″ link=”” linktarget=”_self” alt=”” /][fusion_image image=”https://ismuniv.com/wp-content/uploads/2018/11/Imagers_2182.jpg” image_id=”2218″ link=”” linktarget=”_self” alt=”” /][fusion_image image=”https://ismuniv.com/wp-content/uploads/2018/11/Imagers_0822.jpg” image_id=”2206″ link=”” linktarget=”_self” alt=”” /][fusion_image image=”https://ismuniv.com/wp-content/uploads/2018/11/Imagers_1892.jpg” image_id=”2216″ link=”” linktarget=”_self” alt=”” /][fusion_image image=”https://ismuniv.com/wp-content/uploads/2018/11/Imagers_1782.jpg” image_id=”2214″ link=”” linktarget=”_self” alt=”” /][fusion_image image=”https://ismuniv.com/wp-content/uploads/2018/11/software.jpg” image_id=”2067″ link=”” linktarget=”_self” alt=”” /][fusion_image image=”https://ismuniv.com/wp-content/uploads/2018/11/class.jpg” image_id=”2055″ link=”” linktarget=”_self” alt=”” /][/fusion_images][/fusion_builder_column][/fusion_builder_row][/fusion_builder_container][fusion_builder_container type=”flex” hundred_percent=”no” hundred_percent_height=”no” min_height_medium=”” min_height_small=”” min_height=”” hundred_percent_height_scroll=”no” align_content=”stretch” flex_align_items=”flex-start” flex_justify_content=”flex-start” flex_column_spacing=”” hundred_percent_height_center_content=”yes” equal_height_columns=”no” container_tag=”div” menu_anchor=”” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” status=”published” publish_date=”” class=”” id=”” spacing_medium=”” margin_top_medium=”” margin_bottom_medium=”” spacing_small=”” margin_top_small=”” margin_bottom_small=”” margin_top=”” margin_bottom=”” padding_dimensions_medium=”” padding_top_medium=”” padding_right_medium=”” padding_bottom_medium=”” padding_left_medium=”” padding_dimensions_small=”” padding_top_small=”” padding_right_small=”” padding_bottom_small=”” padding_left_small=”” padding_top=”” padding_right=”” padding_bottom=”” padding_left=”” link_color=”” link_hover_color=”” border_sizes=”” border_sizes_top=”” border_sizes_right=”” border_sizes_bottom=”” border_sizes_left=”” border_color=”” border_style=”solid” box_shadow=”no” box_shadow_vertical=”” box_shadow_horizontal=”” box_shadow_blur=”0″ box_shadow_spread=”0″ box_shadow_color=”” box_shadow_style=”” z_index=”” overflow=”” gradient_start_color=”” gradient_end_color=”” gradient_start_position=”0″ gradient_end_position=”100″ gradient_type=”linear” radial_direction=”center center” linear_angle=”180″ background_color=”” background_image=”” skip_lazy_load=”” background_position=”center center” background_repeat=”no-repeat” fade=”no” background_parallax=”none” enable_mobile=”no” parallax_speed=”0.3″ background_blend_mode=”none” video_mp4=”” video_webm=”” video_ogv=”” video_url=”” video_aspect_ratio=”16:9″ video_loop=”yes” video_mute=”yes” video_preview_image=”” render_logics=”” absolute=”off” absolute_devices=”small,medium,large” sticky=”off” sticky_devices=”small-visibility,medium-visibility,large-visibility” sticky_background_color=”” sticky_height=”” sticky_offset=”” sticky_transition_offset=”0″ scroll_offset=”0″ animation_type=”” animation_direction=”left” animation_speed=”0.3″ animation_offset=”” filter_hue=”0″ filter_saturation=”100″ filter_brightness=”100″ filter_contrast=”100″ filter_invert=”0″ filter_sepia=”0″ filter_opacity=”100″ filter_blur=”0″ filter_hue_hover=”0″ filter_saturation_hover=”100″ filter_brightness_hover=”100″ filter_contrast_hover=”100″ filter_invert_hover=”0″ filter_sepia_hover=”0″ filter_opacity_hover=”100″ filter_blur_hover=”0″][fusion_builder_row][fusion_builder_column type=”1_1″ layout=”1_1″ align_self=”auto” content_layout=”column” align_content=”flex-start” valign_content=”flex-start” content_wrap=”wrap” spacing=”” center_content=”no” link=”” target=”_self” min_height=”” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” sticky_display=”normal,sticky” class=”” id=”” type_medium=”” type_small=”” order_medium=”0″ order_small=”0″ dimension_spacing_medium=”” dimension_spacing_small=”” dimension_spacing=”” dimension_margin_medium=”” dimension_margin_small=”” margin_top=”” margin_bottom=”” padding_medium=”” padding_small=”” padding_top=”” padding_right=”” padding_bottom=”” padding_left=”” hover_type=”none” border_sizes=”” border_color=”” border_style=”solid” border_radius=”” box_shadow=”no” dimension_box_shadow=”” box_shadow_blur=”0″ box_shadow_spread=”0″ box_shadow_color=”” box_shadow_style=”” background_type=”single” gradient_start_color=”” gradient_end_color=”” gradient_start_position=”0″ gradient_end_position=”100″ gradient_type=”linear” radial_direction=”center center” linear_angle=”180″ background_color=”” background_image=”” background_image_id=”” background_position=”left top” background_repeat=”no-repeat” background_blend_mode=”none” render_logics=”” filter_type=”regular” filter_hue=”0″ filter_saturation=”100″ filter_brightness=”100″ filter_contrast=”100″ filter_invert=”0″ filter_sepia=”0″ filter_opacity=”100″ filter_blur=”0″ filter_hue_hover=”0″ filter_saturation_hover=”100″ filter_brightness_hover=”100″ filter_contrast_hover=”100″ filter_invert_hover=”0″ filter_sepia_hover=”0″ filter_opacity_hover=”100″ filter_blur_hover=”0″ animation_type=”” animation_direction=”left” animation_speed=”0.3″ animation_offset=”” last=”true” border_position=”all” first=”true”][fusion_text columns=”” column_min_width=”” column_spacing=”” rule_style=”default” rule_size=”” rule_color=”” content_alignment_medium=”” content_alignment_small=”” content_alignment=”” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” sticky_display=”normal,sticky” class=”” id=”” margin_top=”” margin_right=”” margin_bottom=”” margin_left=”” font_size=”” fusion_font_family_text_font=”” fusion_font_variant_text_font=”” line_height=”” letter_spacing=”” text_color=”” animation_type=”” animation_direction=”left” animation_speed=”0.3″ animation_offset=””]
#Embedded Courses in Bangalore #Embedded Courses in Hyderabad #Embedded Jobs for Freshers #Embedded C #Embedded Systems #Embedded Training in Hyderabad #Embedded Classes in Hyderabad #Embedded Systems Course in Hyderabad #Embedded Programming Courses in Hyderabad #Embedded Training in Bangalore #Embedded Classes in Bangalore #Embedded Systems Course in Bangalore #Embedded Programming Courses in Bangalore #Best Embedded Training Institute in Bangalore #Best Embedded Training Institute in Hyderabad #Embedded Training Institute in Bangalore #Embedded Training Institute in Hyderabad #Best Embedded Course in Bangalore #Best Embedded Course in Hyderabad #best iot training institute in Bangalore #best iot training institute in Hyderabad #iot training institute in bangalore #iot training institute in Hyderabad #best iot course in Bangalore #best iot course in hyderabad #Embedded Jobs in Bangalore #Embedded Jobs in Hyderabad #Iot jobs in Bangalore #IoT jobs in Hyderabad #Python Jobs in Bangalore #Python Jobs in Hyderabad #AIML #Artificial Intelligence #machine learning #Data Science Courses in Bangalore #Data Science Courses in Hyderabad #Data Science Courses #Best Data Science Training Institute #Best Data science Course #Best Python Course #Best Iot Course #Best Iot Training Institute in Bangalore #Best Iot Training Institute in Hyderabad #Iot Certification Course Bangalore #Iot Certification Course Hyderabad #Best Artificial Intelligence Training Institute Bangalore #Best Artificial Intelligence Training Institute Hyderabad #Best fullstack Training Institute in Bangalore #Best full stack Training Institute in Hyderabad #full stack Training Institute in Bangalore #full stack Training Institute in Hyderabad #Best full stack Course in Bangalore #Best full stack Course in Hyderabad
[/fusion_text][/fusion_builder_column][/fusion_builder_row][/fusion_builder_container][fusion_builder_container type=”flex” hundred_percent=”no” hundred_percent_height=”no” min_height_medium=”” min_height_small=”” min_height=”” hundred_percent_height_scroll=”no” align_content=”stretch” flex_align_items=”flex-start” flex_justify_content=”flex-start” flex_column_spacing=”” hundred_percent_height_center_content=”yes” equal_height_columns=”no” container_tag=”div” menu_anchor=”” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” status=”published” publish_date=”” class=”” id=”” spacing_medium=”” margin_top_medium=”” margin_bottom_medium=”” spacing_small=”” margin_top_small=”” margin_bottom_small=”” margin_top=”” margin_bottom=”” padding_dimensions_medium=”” padding_top_medium=”” padding_right_medium=”” padding_bottom_medium=”” padding_left_medium=”” padding_dimensions_small=”” padding_top_small=”” padding_right_small=”” padding_bottom_small=”” padding_left_small=”” padding_top=”” padding_right=”” padding_bottom=”” padding_left=”” link_color=”” link_hover_color=”” border_sizes=”” border_sizes_top=”” border_sizes_right=”” border_sizes_bottom=”” border_sizes_left=”” border_color=”” border_style=”solid” box_shadow=”no” box_shadow_vertical=”” box_shadow_horizontal=”” box_shadow_blur=”0″ box_shadow_spread=”0″ box_shadow_color=”” box_shadow_style=”” z_index=”” overflow=”” gradient_start_color=”” gradient_end_color=”” gradient_start_position=”0″ gradient_end_position=”100″ gradient_type=”linear” radial_direction=”center center” linear_angle=”180″ background_color=”” background_image=”” skip_lazy_load=”” background_position=”center center” background_repeat=”no-repeat” fade=”no” background_parallax=”none” enable_mobile=”no” parallax_speed=”0.3″ background_blend_mode=”none” video_mp4=”” video_webm=”” video_ogv=”” video_url=”” video_aspect_ratio=”16:9″ video_loop=”yes” video_mute=”yes” video_preview_image=”” render_logics=”” absolute=”off” absolute_devices=”small,medium,large” sticky=”off” sticky_devices=”small-visibility,medium-visibility,large-visibility” sticky_background_color=”” sticky_height=”” sticky_offset=”” sticky_transition_offset=”0″ scroll_offset=”0″ animation_type=”” animation_direction=”left” animation_speed=”0.3″ animation_offset=”” filter_hue=”0″ filter_saturation=”100″ filter_brightness=”100″ filter_contrast=”100″ filter_invert=”0″ filter_sepia=”0″ filter_opacity=”100″ filter_blur=”0″ filter_hue_hover=”0″ filter_saturation_hover=”100″ filter_brightness_hover=”100″ filter_contrast_hover=”100″ filter_invert_hover=”0″ filter_sepia_hover=”0″ filter_opacity_hover=”100″ filter_blur_hover=”0″][fusion_builder_row][fusion_builder_column type=”1_1″ layout=”1_1″ align_self=”auto” content_layout=”column” align_content=”flex-start” valign_content=”flex-start” content_wrap=”wrap” spacing=”” center_content=”no” link=”” target=”_self” min_height=”” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” sticky_display=”normal,sticky” class=”” id=”” type_medium=”” type_small=”” order_medium=”0″ order_small=”0″ dimension_spacing_medium=”” dimension_spacing_small=”” dimension_spacing=”” dimension_margin_medium=”” dimension_margin_small=”” margin_top=”” margin_bottom=”” padding_medium=”” padding_small=”” padding_top=”” padding_right=”” padding_bottom=”” padding_left=”” hover_type=”none” border_sizes=”” border_color=”” border_style=”solid” border_radius=”” box_shadow=”no” dimension_box_shadow=”” box_shadow_blur=”0″ box_shadow_spread=”0″ box_shadow_color=”” box_shadow_style=”” background_type=”single” gradient_start_color=”” gradient_end_color=”” gradient_start_position=”0″ gradient_end_position=”100″ gradient_type=”linear” radial_direction=”center center” linear_angle=”180″ background_color=”” background_image=”” background_image_id=”” background_position=”left top” background_repeat=”no-repeat” background_blend_mode=”none” render_logics=”” filter_type=”regular” filter_hue=”0″ filter_saturation=”100″ filter_brightness=”100″ filter_contrast=”100″ filter_invert=”0″ filter_sepia=”0″ filter_opacity=”100″ filter_blur=”0″ filter_hue_hover=”0″ filter_saturation_hover=”100″ filter_brightness_hover=”100″ filter_contrast_hover=”100″ filter_invert_hover=”0″ filter_sepia_hover=”0″ filter_opacity_hover=”100″ filter_blur_hover=”0″ animation_type=”” animation_direction=”left” animation_speed=”0.3″ animation_offset=”” last=”true” border_position=”all” first=”true”][fusion_text columns=”” column_min_width=”” column_spacing=”” rule_style=”default” rule_size=”” rule_color=”” content_alignment_medium=”” content_alignment_small=”” content_alignment=”” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” sticky_display=”normal,sticky” class=”” id=”” margin_top=”” margin_right=”” margin_bottom=”” margin_left=”” font_size=”” fusion_font_family_text_font=”” fusion_font_variant_text_font=”” line_height=”” letter_spacing=”” text_color=”” animation_type=”” animation_direction=”left” animation_speed=”0.3″ animation_offset=””]
Author: Prithvi. [MBA in Digital marketing and Ecommerce]
[/fusion_text][/fusion_builder_column][/fusion_builder_row][/fusion_builder_container]